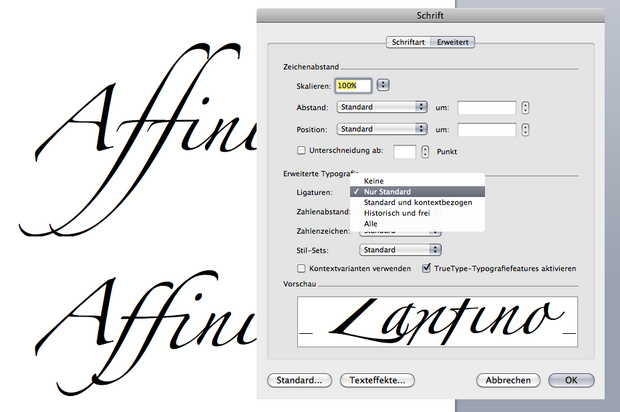
frei …")

Die frühere Beschränkung auf eine Kodierung mit 8 Bit (siehe Teil 2 der Artikelserie) kann diese Forderung nicht erfüllen, da die damit möglichen 256 Zeichen lediglich ausreichen, um einzelne Sprachsysteme abzubilden. Das Mischen beliebiger Sprachen ist damit nicht möglich. Es ist natürlich auch mit 8-Bit-Fonts und -kodierungen denkbar, einen Text zu erstellen, der zum Beispiel russische und griechische Textabschnitte enthält. Diese müssen dazu lediglich mit entsprechenden Fonts (zum Beispiel Helvetica Cyrillic und Helvetica Greek) formatiert werden. In den 1990er Jahren war dies mit den damaligen PostScript-Type1-Fonts gängige Praxis. Doch auch dies kann nur eine Notlösung sein. Denn im Dokument bedienen sich dann zwangsläufig beide Sprachen der gleichen Binärkodes – eine eindeutige Zuordnung eines Kodes zu einem Zeichen ist nicht gegeben. Schon das Öffnen des Dokuments in einer anderen Schriftart würde die Inhalte für den Empfänger unbrauchbar machen.
Eine eindeutige Zeichenkodierung, die unabhängig von Sprachräumen und Rechnerplattformen ist, scheint heute aber unabdingbar – sei es für die Kundendatenbank eines weltweit agierenden Unternehmens oder den Satz einer wissenschaftlichen Arbeit oder eines vielsprachigen Medikamenten-Beipackzettels. Die Lösung dieser Probleme ist so einfach wie nahe liegend. Statt verschiedene Sprachen durch identische Kodes abzubilden, muss ein Standard geschaffen werden, der jedem grafischen Zeichen oder Element aller bekannten Schriftkulturen und Zeichensysteme einen eindeutigen Kode zuordnet. Dieser Standard ist Unicode. Er gibt jedem Zeichen seine eigene Nummer – plattformunabhängig, programmunabhängig und sprachunabhängig.
Die Tragweite dieses Zeichensatzes geht allerdings weit darüber hinaus, einfach nur ein weiterer Industrie-Standard im Wirrwarr der Zeichensätze zu sein. Mit dem ehrgeizigen Ziel, jedem Sinn tragenden Zeichen der Welt eine eindeutige Kodierung zu geben, wird der Unicode gleichsam zum kulturgeschichtlichen Projekt. Selbst Schriftzeichen, die nur von kleinen Menschengruppen benutzt werden, können im Unicode vertreten sein, und Schriftsysteme, die in Zukunft vielleicht außer Gebrauch geraten, werden im Unicode für alle Zeit bewahrt. Der Unicode bildet somit ein dauerhaftes »Museum der Schriftkultur«.
Für die Entwicklung des Standards hat sich das Unicode-Konsortium gegründet, eine gemeinnützige Organisation, deren Mitglieder ein breites Spektrum von Firmen und Institutionen in der datenverarbeitenden Industrie und Informationstechnologie vertreten. Der Unicode-Standard wurde im Jahr 1991 erstmals veröffentlicht. Er wird von führenden Computer-Unternehmen wie Apple, Hewlett-Packard, IBM, Microsoft, Sun und so weiter unterstützt. Es bestehen kaum Zweifel daran, dass sich Unicode zum wichtigsten Kodierungsstandard entwickeln wird – zur Lingua Franca der digitalen Welt. Dennoch ist weder die umfassende Verbreitung noch die Entwicklung des Standards schon völlig abgeschlossen. Unicode wird fortlaufend um neue Zeichen ergänzt. Im Schnitt kommen pro Jahr 1000 neue Zeichen hinzu. In der aktuellen Version 6 sind circa 110.000 Zeichen erfasst. Allerdings bietet der Standard Platz für über eine Million Zeichen.
Wenn Unicodes notiert werden sollen, benutzt man in der Regel eine hexadezimale Darstellung (Ziffern von 0–9, Buchstaben von A–F) mit einem vorangestellten »U+«. Der kleinste Wert ist U+0000, der größte ist U+10FFFF. Dazwischen ist Platz für die besagten eine Million Zeichen. Das kleine Eszett hat beispielsweise den Unicode-Wert U+00DF und das große Eszett, das mit der Unicode-Version 5.1 erschien, hat den Kode U+1E9E. Sobald neue Unicode-Zeichen aufgenommen wurden, sind sie sofort auf allen Unicode-fähigen Geräten anwendbar. Zur Darstellung auf Monitoren und Druckern wird natürlich mindestens ein Font benötigt, der über die neuen Zeichen verfügt. Für den Computer spielt die Darstellung natürlich keine Rolle. Man kann auch Unicode-Zeichen ohne konkrete Darstellung von einer Anwendung zur nächsten kopieren.
Theoretisch kümmert sich Unicode jedoch nur um so genannte »Sinn tragende Zeichen«. Kapitälchen, Schmuckligaturen und ähnliche typografische Besonderheiten, sind für das Unicode-Konsortium nicht interessant, da sie als Glyphenvarianten zu bestehenden Unicode-Zeichen angesehen werden. Diese Zeichen müssen also in der Regel ohne einen Unicode auskommen und sind dann ausschließlich über OpenType-Funktionen ansprechbar. Schriftanbieter haben jedoch die Möglichkeit, diesen Zeichen einen »privaten« Unicode zuzuweisen. Dazu bietet der Unicode-Standard einen besonderen Bereich zur freien Verfügung an: die so genannte Private Use Area (PUA). Werden in Fonts bestimmten Zeichen PUA-Kodes zugewiesen, kann man diese Zeichen also z.B. in der Zeichenpalette/Zeichentabelle des Betriebssystems finden und per Kopieren-und-Einfügen benutzen. Allerdings führt dann gegebenenfalls schon ein Wechsel der Schriftart zu völlig unterschiedlichen Zeichen, da dieser private Bereich eben nicht standardisiert ist.
Welche Zeichen neu aufgenommen werden, hängt natürlich von den Interessen der einreichenden Parteien ab. Nicht jedes der circa 100.000 Zeichen kann wirklich als sprachlich Sinn tragend bezeichnet werden. Gerade im Bereich der Piktogramme finden sich zum Beispiel unzählige Zeichen mit fragwürdiger Relevanz, wie etwa PILE OF POO. Aber auch diese Zeichen sind im »Museum der Schriftkultur« für alle Zeit konserviert. Einmal kodierte Zeichen werden nie wieder entfernt.
Neben dem Unicode-Wert hat jede Kodestelle auch einen eindeutigen englischen Namen, der das Zeichen meist inhaltlich oder notfalls visuell beschreibt. Zwar kann man sich die 100.000 Namen nicht alle merken, aber es hilft bei der Suche nach bestimmten Zeichen durchaus, sich ein wenig mit dem System vertraut zu machen. So lässt sich der Zeichenvorrat in den Tools der Betriebssysteme leicht über den Namen eingrenzen. Im nebenstehend gezeigten Beispiel von Mac OS X werden etwa durch Eingabe des Begriffs »Arrow« automatisch alle kodierten Pfeilsymbole angezeigt. Ein weitere Klick auf einen bestimmten Pfeiltyp zeigt im Anschluss, welche der installierten Schriften über genau diesen Unicode-Pfeil verfügen.
Wer weder Unicode-Wert noch Namen kennt, kann sich durch die verschiedene Unicode-Blöcke hangeln. In diesem Bereichen sind die Zeichen systematisch zusammengefasst; sei es bezogen auf das Schriftsystem (lateinisch, griechisch usw.) oder auf die Art und Funktion der Zeichen (Währungszeichen, diakritische Zeichen usw.)
Unicode ist heute der Standardzeichensatz in Windows, Mac OS, Unix usw. und auch im Internet werden die klassischen 8-Bit-ISO-Zeichensätze immer mehr von Unicode-kodierten Webseiten verdrängt. Daher bereitet der Austausch von mehrsprachigen Dokumenten nach und nach immer weniger Probleme. Und auch Systemschriften und kommerzielle OpenType-Fonts besitzen einen immer größeren Zeichenvorrat, um den gestiegenen Anforderungen der globalen Kommunikation gerecht zu werden. Anwender müssen jedoch darauf achten, in welcher Kodierung verfasste Dokumente weiter gegeben werden. Die alten systembasierten 8-Bit-Kodierungen wie Mac Roman und Windows 1252/ANSI sollten für einen plattformübergreifenden Austausch vermieden werden. Auch ist es wichtig, dass die Information über die verwendete Kodierung im Dokument selbst enthalten ist, damit das öffnende Programm sie auch benutzen kann. TXT-Dateien enthalten zum Beispiel keine Informationen über die verwendete Zeichenkodierung und auch Webseiten werden nicht automatisch mit dieser Information ausgeliefert. Im Zweifel benutzt das Anzeigeprogramm dann einfach die Standardkodierung und Sonderzeichensalat ist nicht selten die Folge.
Weiter Informationen zum Unicode und Übersichten aller kodierten Zeichen gibt es auf der offiziellen Homepage unter http://unicode.org
(Illustration: Kai Meinig)